マッパークラスは、SQLマッパーを定義する時に指定しますが、どのマッパークラスを指定するかによりデータベースアクセス時の振る舞いが変わってきます。
Webtribeではいくつかのマッパークラスを標準で提供していますが、次のように、標準のマッパークラスでは実現できない処理を行う必要がある場合には、要件に応じたマッパークラスを作成し、プロジェクトに登録して使うことができます。
- データベースへのデータの渡し方を変更する必要がある場合
- データベースへからデータの取り出し方を変更する必要がある場合
- データベース製品特有の前処理、後処理を行う必要がある場合
- データベース接続に使用している JDBC ドライバ固有の API を呼び出す必要がある場合
マッパークラスは Java のクラスとして実装し、実行時にDBServerから呼び出されます。
マッパークラスを作成するためには、JDBC のコーディングを行います。
そのため、このドキュメントでは
Webtribe に対する知識の他に、次のような前提知識が必要となります。
- Java プログラムのコーディングおよびコンパイル方法
- コンパイルしたクラスファイルの実行(CLASSPATH の設定等)
- JDK の API(特に JDBC の API)
マッパークラスを作成するために必要なものは、次の通りです。
- Java 開発環境
JDK + エディタ, Eclipse, JBuilder 等
- wedge-common-1.4.0.jar
- wedge-common-server-1.4.0.jar
- wedge-optional-1.4.0.jar
- wedge-run-common-1.4.0.jar
- wedge-run-data-1.4.0.jar
- wedge-run-server-1.4.0.jar
マッパークラスのコンパイルに必要な class ファイルを含んでいます。
Webtribeの WEB-INF/lib ディレクトリにあります。
ここでは例として、テーブルから全レコードを削除するマッパークラスのコーディングについて説明します。
全レコードを削除するだけですので、入力アイテム、出力アイテムとも使いません。(絞込み条件や処理結果のデータが発生しないためです。)
マッパークラスに定義された内容を実行するだけの処理となります。
SQLマッパーに定義された SQL が
DELETE FROM WORKTABLE
といった SQL になる場合、この SQL には入力パラメータ、出力パラメータのいずれも必要ありません。そこで、入力アイテム、出力アイテムの処理は行っていません。
 補足
補足
ひとつのマッパークラスで、入力アイテムがある場合も、ない場合も、それぞれの場合に応じた処理を行えるような記述をすることは可能ですが、ここではまずマッパークラスとして、最低限どのような記述が必要かということをご理解いただくために、入力アイテムをチェックする、といった処理は行っていません。
上記 SQL を実行するために必要なマッパークラスの処理は次のようになります。
1: package samples;
2: import java.sql.SQLException;
3: import java.sql.Statement;
4: import jp.ne.mki.wedge.run.db.dc.SqlDataControl;
5: import jp.ne.mki.wedge.run.interfaces.DataInterface;
6: import jp.ne.mki.wedge.run.interfaces.DcRequest;
7:
8: public class SimpleDeleteDc extends SqlDataControl {
9:
10: protected DataInterface[] executeSql(DcRequest req) throws SQLException {
11: int updatedRecordCount = 0;
12: Statement stmt = null;
13:
14: try {
15: stmt = req.createStatement();
16: updatedRecordCount = stmt.executeUpdate(req.getSql());
17: req.setUpdateErrorLine(0);
18: } catch (SQLException ex) {
19: req.setUpdateErrorLine(1);
20: throw ex;
21: } finally {
22: req.setUpdateTargetCount(0);
23: req.setDbAccessCount(1);
24: req.setDbUpdatedCount(updatedRecordCount);
25:
26: req.closeDbObject(stmt);
27: }
28:
29: return null;
30: }
31: }
- 8行目 : SqlDataControl
マッパークラスは、SqlDataControlを継承して作成します。SqlDataControl は抽象クラスで、継承先のクラスは executeSql メソッドを実装する必要があります。
ApServerから呼び出されたDBServerは、必要な前処理を行った後、マッパークラスの executeSql メソッドを呼び出し、後処理を行ってから、処理結果を ApServer に返します。
- 10行目 : DcRequest req
executeSql メソッドにはパラメータとして DcRequest のインスタンスが渡されます。
DcRequest には マッパークラス で処理を行う上で必要な機能が用意されています。SQLマッパーに指定された入力アイテムの値や、DB変換クラスの取得、java.sql.PreparedStatement の作成、コントロールレコードへの値の設定等は、DcRequest に用意されたメソッドを使って行います。
- 15行目 : stmt = req.createStatement();
このサンプルでは java.sql.Statement を使って SQL を処理します。
java.sql.Statement のインスタンスを取得するために、DcRequest の createStatement メソッドを呼び出します。
- 16行目 : updatedRecordCount = stmt.executeUpdate(req.getSql());
SQLマッパー で指定された SQL を取得するために、DcRequest の getSql メソッドを呼び出します。
取得した SQL を使って java.sql.Statement の executeUpdate メソッドを呼び出します。
executeUpdate メソッドは、更新されたレコード件数を返しますので、この値を変数 updatedRecordCount に保持しておきます。
- 17行目 : req.setUpdateErrorLine(0);
更新処理(executeUpdate メソッド)がエラーなく完了した場合、処理の制御が 17行目に到達しますので、ここで DcRequest の setUpdateErrorLine メソッドを呼び出し、コントロールレコードの「エラーが発生した行番号」に 0 をセットします。
補足更新処理でエラーが発生した場合は、18行目の catch に処理の制御が移ります。
- 19行目 : req.setUpdateErrorLine(1);
19行目に処理の制御が遷移したということは、更新処理でエラーが発生したということになります。
そこで、コントロールレコードの「エラーが発生した行番号」に 1 をセットします。
- 20行目 : throw ex;
継承元である SqlDataControl にはエラー処理が用意されています。
マッパークラスでエラー処理を行うこともできますが、標準で提供されているエラー処理を実行する場合は、例外オブジェクトをそのままスローします。それにより、executeSql メソッドの呼出し元でスローされた例外がキャッチされ、標準で提供されているエラー処理が実行されます。
補足
標準で実行される例外処理は次のようになります。
- コントロールレコードの「DBエラーコード」にスローされた例外オブジェクトの DB エラーコードをセット
- コントロールレコードの「DBステータス」にスローされた例外オブジェクトの DB ステータスをセット
- コントロールレコードの「DBエラーメッセージ」にスローされた例外オブジェクトのメッセージをセット
- コンロトールレコードの処理ステータスに「エラー」をセット
- エラーログを出力
- 22行目 : req.setUpdateTargetCount(0);
コントロールレコードの「更新対象行数」に 0 をセットします。
補足コントロールレコードの「更新対象行数」には、入力アイテムの行数をセットします。
- 23行目 : req.setDbAccessCount(1);
コントロールレコードの「データベースアクセス回数」に 1 をセットします。
補足コントロールレコードの「データベースアクセス回数」には、データベースに対して SQL を発行した回数をセットします。
- 24行目 : req.setDbUpdatedCount(updatedRecordCount);
コントロールレコードの「更新レコード数」に updatedRecordCount(executeUpdate メソッドの戻り値)をセットします。
補足コントロールレコードの「更新レコード数」には、マッパークラスを実行した結果、更新されたレコードの件数をセットします。
- 26行目 : req.closeDbObject(stmt);
DcRequest の closeDbObject メソッドを呼び出し、java.sql.Statement のインスタンスをクローズします。
補足
closeDbObject では次の処理を行っています。
- 渡されたオブジェクト(stmt)が null かどうかのチェック
- 渡されたオブジェクト(stmt)が null でない場合は、クローズ
- クローズした時に例外が発生した場合は、次の処理を実行
- コントロールレコードの「DBエラーコード」にスローされた例外オブジェクトの DB エラーコードをセット
- コントロールレコードの「DBステータス」にスローされた例外オブジェクトの DB ステータスをセット
- コントロールレコードの「DBエラーメッセージ」にスローされた例外オブジェクトのメッセージをセット
- エラーログを出力
- 29行目 : return null;
この マッパークラス では ApServer に返すデータがありません(出力アイテムが指定されていません)ので、executeSql メソッドの呼出し元に null を返します。
次に入力アイテムを処理するマッパークラスのコーディングについて説明します。
ここでは例として、次のような
UPDATE WORKTABLE SET NAME=? WHERE ID=?
といった、指定された条件に該当するレコードに対してだけ、値を更新する SQL を実行します。
上記の SQL を処理するために、先ほどのコーディングと比べて、入力アイテムの処理が追加されています。
1: package samples;
2: import java.io.IOException;
3: import java.sql.PreparedStatement;
4: import java.sql.SQLException;
5: import java.text.ParseException;
6: import jp.ne.mki.wedge.run.db.dc.SqlDataControl;
7: import jp.ne.mki.wedge.run.interfaces.DBDataConvertInterface;
8: import jp.ne.mki.wedge.run.interfaces.DataInterface;
9: import jp.ne.mki.wedge.run.interfaces.DcRequest;
10:
11: public class SimpleUpdateDc extends SqlDataControl {
12:
13: protected DataInterface[] executeSql(DcRequest req) throws SQLException, ParseException, IOException {
14: PreparedStatement stmt = null;
15: int colCount = req.getColumns();
16: int rowCount = req.getRows();
17: int updatedCount = 0;
18: int updatedRecordCount = 0;
19: int errorRowNo = 0;
20:
21: try {
22: DataInterface[] inItemArray = req.getInputRecordArray();
23: DBDataConvertInterface[] dbCvIn = req.getInDbCvClassArray();
24: stmt = req.prepareStatement();
25: // stmt = req.prepareStatement(req.getSql());
26:
27: for (int ii = 0; ii < rowCount; ii++) {
28: errorRowNo++;
29:
30: for (int jj = 0; jj < colCount; jj++) {
31: String data = inItemArray[jj].getString(ii);
32: if (dbCvIn[jj] instanceof DBDataConvert) {
33: ((DBDataConvert) dbCvIn[jj]).setObject(stmt, jj + 1, data);
34: } else {
35: dbCvIn[jj].setData(stmt, jj + 1, data);
36: }
37: }
38:
39: int count = stmt.executeUpdate();
40: if (count > 0) {
41: updatedCount++;
42: updatedRecordCount += count;
43: }
44: }
45: req.setUpdateErrorLine(0);
46: } catch (SQLException ex) {
47: req.setUpdateErrorLine(errorRowNo);
48: throw ex;
49: } finally {
50: req.setUpdateTargetCount(rowCount);
51: req.setDbAccessCount(updatedCount);
52: req.setDbUpdatedCount(updatedRecordCount);
53:
54: req.closeDbObject(stmt);
55: }
56:
57: return null;
58: }
59: }
次に、全件検索の SQL を例にとり、出力アイテムを使ったマッパークラスのコーディングについて説明します。
ここでは例として次のような SQL を実行します。
SELECT ID, NAME FROM WORKTABLE
ID, NAME という 2つのカラムが検索対象となっていますので、この 2つのカラムを出力アイテムにセットするためのコーディングが追加されています。
1: package samples;
2: import java.io.IOException;
3: import java.sql.ResultSet;
4: import java.sql.SQLException;
5: import java.sql.Statement;
6: import jp.ne.mki.wedge.run.db.dc.SqlDataControl;
7: import jp.ne.mki.wedge.run.interfaces.DBDataConvertInterface;
8: import jp.ne.mki.wedge.run.interfaces.DataInterface;
9: import jp.ne.mki.wedge.run.interfaces.DcRequest;
10:
11: public class SimpleQueryAllRecordsDC extends SqlDataControl {
12:
13: protected DataInterface[] executeSql(DcRequest req) throws SQLException, IOException {
14: DataInterface[] outItemArray = null;
15: int readRowCount = 0;
16: Statement stmt = null;
17: ResultSet rs = null;
18:
19: try {
20: stmt = req.createStatement();
21: rs = stmt.executeQuery(req.getSql());
22: int outColumnCount = rs.getMetaData().getColumnCount();
23: outItemArray = createOutputDataArray(outColumnCount);
24: DBDataConvertInterface[] dbCvOut = req.getOutDbCvClassArray();
25: while (rs.next()) {
26: for (int ii = 0; ii < outColumnCount; ii++) {
27: String data;
28: if (dbCvOut[ii] instanceof DBDataConvert) {
29: data = ((DBDataConvert) dbCvOut[ii]).getObject(rs, ii + 1);
30: } else {
31: data = dbCvOut[ii].getData(rs, ii + 1);
32: }
33: outItemArray[ii].addString(data);
34: }
35: readRowCount++;
36: }
37: } finally {
38: req.setDbAccessCount(readRowCount);
39: req.closeDbObject(rs);
40: req.closeDbObject(stmt);
41: }
42:
43: return outItemArray;
44: }
45: }
- 20行目 : stmt = req.createStatement();
この例では SQL に渡すパラメータ(絞込み条件)はありませんので、java.sql.Statement のインスタンスを取得します。
- 21行目 : rs = stmt.executeQuery(req.getSql());
SQLマッパー で設定された検索 SQL を発行し、戻り値を ResultSet の変数にセットします。
- 22行目 : int outColumnCount = rs.getMetaData().getColumnCount();
java.sql.ResultSetMetaData を使って、検索結果(SQL 実行結果)の項目数(カラム数)を取得します。
ここで取得した項目数を使って、ApServerに返すデータを初期化します。
- 23行目 : outItemArray = createOutputDataArray(outColumnCount);
ApServerに返すデータを格納するためのインスタンスを生成します。
createOutputDataArray は、引数に指定された数だけ、DataInterface の配列を作成して返します。
- 24行目 : DBDataConvertInterface[] dbCvOut = req.getOutDbCvClassArray();
出力アイテム用DB変換クラスを取得します。
DcRequest の getOutDbCvClassArray メソッドは、DB変換クラスのインスタンスを配列で返します。
- 25行目 : while (rs.next()) {
検索結果(java.sql.ResultSet)が、次のレコードを返す間(まだ読み込んでいないレコードが残っている間)、処理を繰り返します。
- 26行目 : for (int ii = 0; ii < outColumnCount; ii++) {
検索結果項目の数だけループを繰り返し、検索結果のデータを出力アイテムにセットしていきます。
- 29行目 : String data = dbCvOut[ii].getData(rs, ii + 1);
DB変換クラスが 1.1からサポートされた新しいインターフェースを実装している場合は getObject メソッドを呼び出して、ii 番目の項目を取得します。
DB変換クラス の getObject メソッドは、データベースから検索した、変換後のデータを返します。
- 31行目 : String data = dbCvOut[ii].getData(rs, ii + 1);
DB変換クラスが 1.1からサポートされた新しいインターフェースを実装していない場合は getData メソッドを呼び出して、ii 番目の項目を取得します。
DB変換クラス の getData メソッドは、データベースから検索した、変換後のデータを返します。
- 28行目 : outItemArray[ii].addString(data);
ii 番目の出力アイテムに、検索結果(DB変換クラスによる変換後)のデータをセットします。
- 35行目 : readRowCount++;
読み込み行数(レコード数)をカウントアップします。
- 38行目 : req.setDbAccessCount(readRowCount);
コントロールレコードに読み込み行数(レコード数)をセットします。
- 39行目 : req.closeDbObject(rs);
java.sql.ResultSet のインスタンスをクローズします。
- 43行目 : return outItemArray;
出力アイテムを呼出し元に返します。
呼出し元は、このデータをApServer返します。
次に、絞込み条件付き検索の SQL を例にとり、入力アイテム出力アイテムを使ったマッパークラスのコーディングについて説明します。
ここでは例として次のような SQL を実行します。
SELECT NAME FROM WORKTABLE WHERE ID=?
ここでは ID カラムに検索条件を設定し、NAME カラムのデータを検索しますので、マッパークラスは、入力アイテムをセットし、出力アイテムを受け取る処理を行います。
条件指定項目の行数だけ検索処理を繰り返し、検索結果の行数だけデータを取得し、検索結果の行に含まれる項目数だけ出力アイテムに値をセットしますので、下記例では 3重の入れ子になったループを行っています。
1: package samples;
2: import java.io.IOException;
3: import java.sql.PreparedStatement;
4: import java.sql.ResultSet;
5: import java.sql.SQLException;
6: import java.text.ParseException;
7: import jp.ne.mki.wedge.run.db.dc.SqlDataControl;
8: import jp.ne.mki.wedge.run.interfaces.DBDataConvertInterface;
9: import jp.ne.mki.wedge.run.interfaces.DataInterface;
10: import jp.ne.mki.wedge.run.interfaces.DcRequest;
11:
12: public class SimpleQueryDC extends SqlDataControl {
13:
14: protected DataInterface[] executeSql(DcRequest req) throws SQLException, ParseException, IOException {
15:
16: int rowCount = req.getRows();
17: DataInterface[] outItemArray = null;
18: int readRowCount = 0;
19:
20: DataInterface[] inItemArray = req.getInputRecordArray();
21: PreparedStatement stmt = null;
22:
23: try {
24: int colCount = req.getColumns();
25: DBDataConvertInterface[] dbCvIn = req.getInDbCvClassArray();
26: DBDataConvertInterface[] dbCvOut = req.getOutDbCvClassArray();
27: stmt = req.prepareStatement();
28:
29: for (int ii = 0; ii < rowCount; ii++) {
30: for (int jj = 0; jj < colCount; jj++) {
31: String data = inItemArray[jj].getString(ii);
32: if (dbCvIn[jj] instanceof DBDataConvert) {
33: ((DBDataConvert) dbCvIn[jj]).setObject(stmt, jj + 1, data);
34: } else {
35: dbCvIn[jj].setData(stmt, jj + 1, data);
36: }
37: }
38:
39: ResultSet rs = null;
40:
41: try {
42: rs = stmt.executeQuery();
43: int outColumnCount = rs.getMetaData().getColumnCount();
44: if (outItemArray == null) {
45: outItemArray = createOutputDataArray(outColumnCount);
46: }
47:
48: while (rs.next()) {
49: for (int jj = 0; jj < outColumnCount; jj++) {
50: String data;
51: if (dbCvOut[jj] instanceof DBDataConvert) {
52: data = ((DBDataConvert) dbCvOut[jj]).getObject(rs, jj + 1);
53: } else {
54: data = dbCvOut[jj].getData(rs, jj + 1);
55: }
56: outItemArray[jj].addString(data);
57: }
58: readRowCount++;
59: }
60: } finally {
61: req.closeDbObject(rs);
62: }
63: }
64: } finally {
65: req.setDbAccessCount(readRowCount);
66: req.closeDbObject(stmt);
67: }
68:
69: return outItemArray;
70: }
71: }
- 29行目 : for (int ii = 0; ii < rowCount; ii++) {
入力アイテムで渡された行数だけ繰り返します。
- 48行目 : while (rs.next()) {
SQL を実行した結果、検索された行数だけ繰り返します。
- 49行目 : for (int jj = 0; jj < outColumnCount; jj++) {
検索結果の項目数分だけ、繰り返します。
ここでは表タイプを使って、PL/SQL に配列を渡し、結果も配列で受け取るためのサンプルについて説明します。
 注意
注意
下記サンプルは Oracle 8i を動作を確認しています。
基本的には Oracle 9i でも動作しますが、このサンプルは Oracle に依存したコーディングをしているため、Oracle のバージョンや JDBC ドライバのバージョンによってはうまく動作しないケースも考えられます。
また、下記コードを実行する場合は、あらかじめDBServerの CLASSPATH に Oracle 社から提供される NLS 対応 JDBC ドライバを追加しておく必要があります。
 Example...
Example...
- setenv.bat
set RUNJDBC=c:\jdbc\nls_charset12.zip;c:\jdbc\classes12.zip
- setenv.sh
RUNJDBC=/opt/jdbc/nls_charset12.zip:/opt/jdbc/classes12.zip
- Common.ini
RUNJDBC=c:\jdbc\nls_charset12.zip;c:\jdbc\classes12.zip
このサンプルでは、PL/SQL と配列を受け渡しするために、次のような作業を行い、
- 表タイプを作成
- 表タイプを使ったパッケージを作成
- 表タイプを使ったパッケージ本体を作成
作成したパッケージに記述されたプロシージャを、Java から呼び出す処理を行っています。
Java からプロシージャを呼び出す時に、あらかじめ作成しておいた表タイプを指定します。
- 表タイプ作成
create or replace type StringList as table of varchar2(16);
16桁の可変文字列を要素として保持する表タイプを、「StringList」という名称で定義します。
- パッケージ作成
create or replace package array as
procedure ReverseStringList(InputString in StringList, OutputString out StringList);
end array;
表タイプ「StringList」を入力項目、出力項目として受け渡しするプロシージャを パッケージ「array」に「ReverseStringList」という名称で定義します。
- パッケージ本体作成
create or replace package body array as
procedure ReverseStringList(InputString in StringList, OutputString out StringList) as
ListCount number(3);
ii number(3);
idx number(3);
begin
ListCount := InputString.count;
OutputString := StringList();
OutputString.extend(ListCount);
idx := ListCount;
FOR ii IN 1..ListCount LOOP
OutputString(ii) := InputString(idx);
idx := idx - 1;
END LOOP;
end ReverseStringList;
end array;
受け取った可変文字列の配列を、逆の順番に並び替えて呼び出し元に返すプロシージャを定義します。
このプロシージャを呼び出すマッパークラスのサンプルは、次のようになります。
1: package samples;
2: import java.sql.Array;
3: import java.sql.CallableStatement;
4: import java.sql.SQLException;
5: import java.sql.Types;
6:
7: import oracle.sql.ARRAY;
8: import oracle.sql.ArrayDescriptor;
9: import jp.ne.mki.wedge.run.db.dc.SqlDataControl;
10: import jp.ne.mki.wedge.run.interfaces.DataInterface;
11: import jp.ne.mki.wedge.run.interfaces.DcRequest;
12:
13: public class SimpleSpDC extends SqlDataControl {
14: private final static String TABLE_TYPE_NAME = "STRINGLIST";
15: private final static String SQL = "{call array.ReverseStringList(?,?)}";
16:
17: protected DataInterface[] executeSql(DcRequest req) throws SQLException {
18: CallableStatement stmt = null;
19: DataInterface[] inItemArray = req.getInputRecordArray();
20: String[] inStringArray = null;
21: DataInterface[] outItemArray = null;
22:
23: try {
24: int itemSize = inItemArray[0].getSize();
25: inStringArray = new String[itemSize];
26: for (int ii = 0; ii < itemSize; ii++) {
27: String data = inItemArray[0].getString(ii);
28: inStringArray[ii] = data;
29: }
30:
31: stmt = req.prepareCall(SQL);
32: ArrayDescriptor desc = ArrayDescriptor.createDescriptor(TABLE_TYPE_NAME, stmt.getConnection());
33: ARRAY arrayIn = new ARRAY(desc, stmt.getConnection(), inStringArray);
34: stmt.setArray(1, arrayIn);
35: stmt.registerOutParameter(2, Types.ARRAY, TABLE_TYPE_NAME);
36: stmt.execute();
37:
38: Array arrayOut = stmt.getArray(2);
39: String[] stringArray = (String[]) arrayOut.getArray();
40: outItemArray = createOutputDataArray(1);
41: int outSize = stringArray.length;
42: DataInterface di = outItemArray[0];
43: for (int ii = 0; ii < outSize; ii++) {
44: di.addString(stringArray[ii]);
45: }
46: } finally {
47: req.closeDbObject(stmt);
48: }
49:
50: return outItemArray;
51: }
52: }
- 14行目 : private final static String TABLE_TYPE_NAME = "STRINGLIST";
JDBC で配列を受け渡しする時に使う表タイプの名称を定数として定義します。
Oracle では表タイプは大文字として扱われ、実行時には大文字/小文字が区別されるようですので、大文字で定義しておきます。
-
15行目 : private final static String SQL = "{call array.ReverseStringList(?,?)}";
PL/SQL を呼び出すための SQL を定数として定義します。
- 24行目 : int itemSize = inItemArray[0].getSize();
入力アイテムに格納されたデータの行数を取得します。
PL/SQL に可変文字列を配列で渡す際、入力アイテム(DataInterface の配列)のままで PL/SQL に渡すことはできないので、いったん java.lang.String クラスの配列に代入しておく必要があります。ここで取得した行数分の要素数をもつ java.lang.String クラスの配列を生成します。
- 25行目 : inStringArray = new String[itemSize];
入力アイテムに格納された行数分だけデータを格納できる java.lang.String クラスの配列を生成します。
- 26行目 : for (int ii = 0; ii < itemSize; ii++) {
生成した java.lang.String クラスの配列に、入力アイテムの内容をセットするため、入力アイテムの行数分だけ繰り返します。
- 27行目 : String data = inItemArray[0].getString(ii);
入力アイテム(0 はひとつ目の項目)から ii 行目のデータを取り出します。
- 28行目 : inStringArray[ii] = data;
入力アイテムから取り出したデータを java.lang.String クラスの配列に格納します。
- 31行目 : stmt = req.prepareCall(SQL);
DcRequest の prepareCall メソッドを呼び出し、java.sql.CallableStatement を取得します。
- 32行目 : ArrayDescriptor desc = ArrayDescriptor.createDescriptor(TABLE_TYPE_NAME, stmt.getConnection());
表タイプ名、JDBC コネクション(java.sql.Connection)を引数にして、oracle.sql.ArrayDescriptor のインスタンスを取得します。
- 33行目 : ARRAY arrayIn = new ARRAY(desc, stmt.getConnection(), inStringArray);
oracle.sql.ArrayDescriptor、JDBC コネクション(java.sql.Connection)、PL/SQL に渡す可変文字列を格納した java.lang.String クラスの配列を oracle.sql.ARRAY のコンストラクタに渡して、oracle.sql.ARRAY のインスタンスを生成します。
oracle.sql.ARRAY は java.sql.Array インターフェースを実装したクラスです。
- 34行目 : stmt.setArray(1, arrayIn);
PL/SQL の 1つ目の引数に可変文字列を格納した配列を渡します。
-
35行目 : stmt.registerOutParameter(2, Types.ARRAY, TABLE_TYPE_NAME);
PL/SQL の 2つ目の引数のデータ型を設定します。
ここでは SQL タイプとして java.sql.Types.Array(配列型)、タイプ名として表タイプ名を設定しています。
-
36行目 : stmt.execute();
SQL を実行して、PL/SQL を呼び出します。
- 38行目 : Array arrayOut = stmt.getArray(2);
java.sql.CallableStatement の getArray メソッドを呼び出し、PL/SQL の 2番目の項目にセットされたデータを取得します。
- 39行目 : String[] stringArray = (String[]) arrayOut.getArray();
PL/SQL から返ってきた配列を java.lang.String クラスの配列として取得します。
-
40行目 : outItemArray = createOutputDataArray(1);
出力アイテムの項目数分だけ DataInterface の配列を生成します。
ここでは、出力アイテムの項目数はひとつですので、引数に 1 を指定します。
-
42行目 : DataInterface di = outItemArray[0];
DataInterface の配列から 1番目の要素(ひとつ目の項目)を取得します。
-
43行目 : for (int ii = 0; ii < outSize; ii++) {
PL/SQL から取得したデータ(配列)の要素数だけ繰り返します。
-
44行目 : di.addString(stringArray[ii]);
PL/SQL から取得したデータ(配列)の ii 番目のデータを、出力アイテムにセットします。
実装したマッパークラスを使うためには、いくつかの設定が必要となります。
ここでは、SimpleQueryDC を使う場合の手順について説明します。
まずマッパークラスのソースをコンパイルして class ファイルを生成します。
コンパイルを行うには、IDE(統合開発環境)を使う方法と、JDK を使う方法がありますが、IDE の場合は、IDE のツールによって設定が異なりますので、ここでは JDK を使ってコンパイルを行う方法について説明します。
コンパイルを行うには、CLASSPATH に wedge-common-1.4.0.jar, wedge-common-server-1.4.0.jar, wedge-optional-1.4.0.jar, wedge-run-common-1.4.0.jar, wedge-run-data-1.4.0.jar, wedge-run-server-1.4.0.jar を設定します。
Example...
[Java 6 を使って SimpleQueryDC.java をコンパイルする場合]
コマンドプロンプトを開いて、次のコマンドを実行します。
set JAVA_HOME=c:\jdk1.7.0_13
set PATH=%JAVA_HOME%\bin;%PATH%
set CLASSPATH=c:\Tomcat6.0\webapps\webtribe\WEB-INF\lib\wedge-common-1.4.0.jar;\WEB-INF\lib\wedge-common-server-1.4.0.jar;\WEB-INF\lib\wedge-optional-1.4.0.jar;\WEB-INF\lib\wedge-run-common-1.4.0.jar;\WEB-INF\lib\wedge-run-data-1.4.0.jar;\WEB-INF\lib\wedge-run-server-1.4.0.jar
javac SimpleQueryDC.java
コンパイルが通ると、SimpleQueryDC.class というファイルが作成されます。
- Data Management ConsoleのSQLマッパータブを開き、「ワークテーブル」の「QUERY」を選択します。
●図4. [DMC登録]
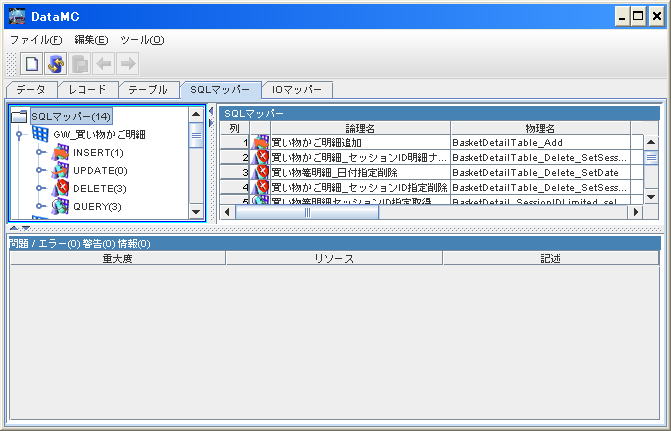
- 「SELECT NAME FROM WORKTABLE WHERE ID=?」という SQL を実行しますので、下記のようなSQLマッパーを登録します。
補足
事前に ID, NAME カラムをデータ型タブに、WORKTABLE の構造をレコードタブとテーブルタブに登録しておく必要があります。
今回使った WORKTABLE は次のように定義しました。
create table worktable (
id number(7) not null,
name varchar2(16),
version varchar2(16)
);
alter table worktable add constraint pk_worktable primary key (id);
insert into worktable values(1,'Sparkler','1.1.4');
insert into worktable values(2,'Pumpkin','1.1.5');
insert into worktable values(3,'Abigail','1.1.6');
insert into worktable values(4,'Brutus','1.1.7');
insert into worktable values(5,'Chelsea','1.1.8');
insert into worktable values(6,'Playground','1.2');
insert into worktable values(7,'Cricket','1.2.2');
insert into worktable values(8,'Kestrel','1.3');
insert into worktable values(9,'Ladybird','1.3.1');
insert into worktable values(10,'Merlin','1.4.0');
insert into worktable values(11,'Hopper','1.6.0');
insert into worktable values(12,'Mantis','1.4.2');
insert into worktable values(13,'Tiger','1.5.0');
insert into worktable values(14,'DragonFly','1.5.1');
insert into worktable values(15,'Mustang','1.6.0');
commit;
●図5. [定義入力タブ]
●図6. [入出力データセットタブ]
- 作成したSQLマッパーを使ったトランザクションもServer Application Management Consoleに登録しておきます。
コンパイルしたマッパークラスのクラスファイル(SimpleQueryDC.class)をコピーします。
Example...
SimpleQueryDC.class を WEB-INF/classes/samples にコピー
Windows の場合
md c:\Tomcat6.0\webapps\webtribe\WEB-INF\classes
md c:\Tomcat6.0\webapps\webtribe\WEB-INF\classes\samples
copy SimpleQueryDC.class c:\Tomcat6.0\webapps\webtribe\WEB-INF\classes\samples
Linux の場合
mkdir -p /opt/jakarta-tomcat-6.0/webapps/webtribe/WEB-INF/classes/samples
cp SimpleQueryDC.class /opt/jakarta-tomcat-6.0/webapps/webtribe/WEB-INF/classes/samples
classes ディレクトリを CLASSPATH に追加します。
DBServerを再起動し、CLASSPATH の設定を有効にします。
トランザクションテスト等で作成したSQLマッパーを実行し、動作を確認します。
トレースログで、作成したSQLマッパーが呼び出されているかどうか確認することができます。
●図7. [トランザクションテスト]
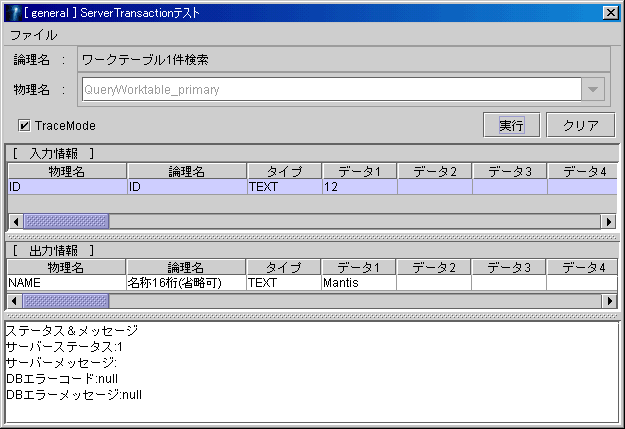
[トレースログ]
[2004/05/10 19:49:51]
*DC Class
[samples.SimpleQueryDC]
*SQL
[SELECT NAME FROM WORKTABLE WHERE ID = ? ]
*Input DB convert class
[]
*Input data
[12]
*Output DB convert class
[]
*Output data
[Mantis]