
Vista文字とチェック方法
WindowsVistaでは JIS X 0213:2004 の対応が行われ、MSゴシックとMS明朝のアップデートが行われています。
また、新しいフォントとして メイリオ が標準搭載されています。
メイリオ(Meiryo)はWindows Vistaに標準で搭載されているClearType対応日本語フォントです。
より細かい階調制御で文字のジャギーを減らし、曲線もきれいに表示できるという特色があります。
このページでは、これら変更による Java上の影響や注意点をまとめていきます。
フォント規格
WindowsVistaでは、JIS X 2013:2004(通称:JIS2004) に対応したフォントが標準搭載されています。
| Windowsバージョン | Unicodeバージョン | 対応JIS規格 |
|---|---|---|
| Window 98 | 非対応 | JIS X 0208:1990 JIS X 0212:1990 |
| Windows NT 4.0 SP4 | Unicode 2.0 | |
| Windows 2000 | Unicode 2.1 | |
| Windows XP | Unicode 3.0 | |
| Windows Server 2003 | ||
| Windows Vista | Unicode 3.2 | JIS X 0208:1990 JIS X 0212:1990 JIS X 0213:2004 |
JIS X 2013:2004を、以前のフォントと比較すると以下の特徴があります。
- 字形変更
同じ文字でも、表示するマシンのフォントバージョンにより、字体が異なる場合が出てきます。
WindowsXP の場合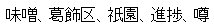
WindowsVista の場合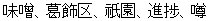
- 拡張文字
第3,4水準漢字、非漢字にて追加された文字があります。 追加された文字は、JIS X 2013:2004非対応環境では文字化けする場合があります。U+03402 の文字を表示すると・・・
WindowsXP の場合
WindowsVista の場合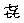
- サロゲート ペア
サロゲートと呼ばれる 16ビットの2つのコードを組み合わせて1つの文字を表現します。 JIS X 2013:2004非対応のWindowsXPなどでは、文字化けします。U+2000B,U+21336,U+2044A の文字を表示すると・・・
WindowsXP の場合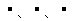
WindowsVista の場合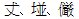
- 結合文字
基底文字(16ビット)と結合文字(16ビット)を組み合わせることにより、サロゲートペア同様32ビットで1文字を表現します。 結合文字単体では 意味を持たないコードになるので、JIS X 2013:2004非対応のWindowsXPなどでは 2文字目だけ文字化け します。結合文字U+309A(゜) を使い、「カ + U+309A」、「キ + U+309A」 の文字を表示すると・・・
WindowsXP の場合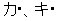
WindowsVista の場合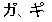
Javaにおける文字の扱いについて
Javaでは、Unicodeにて文字を扱います。
そのため、Java内部では JIS X 2013の文字についても取り扱うことができます。
しかし、外部からの入出力の際には文字セットを意識する必要があります。
たとえば、ファイル入出力 や HTTPなどでのデータ送受信 時などでは、正しい文字セットを認識し、
JavaのUnicodeの世界に格納してあげる必要があります。
WindowsVistaで採用された JIS X 2013 での サロゲートペア、結合文字 については、
文字列操作関連に注意が必要です。
これらの文字は 1文字を2文字分の領域を使って表現しているため、String#getLength()
にて長さを取得すると 1文字なのに 長さが2 になります。
この対応として、「コードポイント」という概念が導入されており、サロゲートペア、結合文字の文字列操作は
「コードポイント」により操作を行う必要があります。
MS932のみの文字を判定
文字セットがMS932で認識できる文字かどうか? という判定を行います。
これにより、MS932では扱えない文字(サロゲートペアなど)がないかどうかを確認することができます。
判定は、MS932で エンコード/デコード して結果が同じかどうか にて行います。
Javaでは以下のようになります。
※より良い判定方法があれば、ご連絡いただけると幸いです。
サロゲートペア判定
サロゲートペアの文字かどうか?を判断するためのメソッドとして、
Character.isHighSurrogate,
Character.isLowSurrogate
が用意されていますので、これを使用します。
サロゲートペアの扱いの注意点
サロゲートペア は 2つの文字を組み合わせて1つの文字を生成するため、 文字桁数 や 文字バイト数 を取得して使用しているプログラムでは注意が必要です。
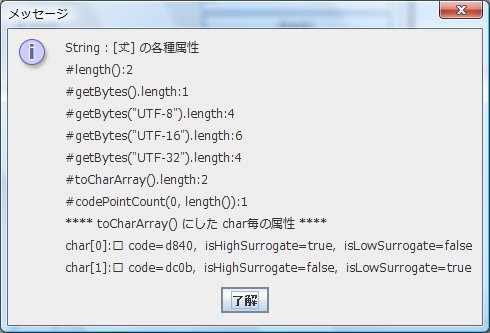
サロゲートペアである 0x0002000B の文字情報を Javaにて取得すると、
上図のようになります。
通常、漢字1文字では String#length() = 1 になりますが、String#length() = 2 になっているのが分かります。
また、String#getBytes().length = 1 になってしまっているのもわかります。
サロゲートペア文字を使用するアプリケーションの場合は、長さを取得する部分を変更する必要がありそうです。
String#getLength() の場合は、変わりとなるメソッドは Character.codePointCount
が使用できます。
バイト数(String#getByte().length)を取得している場合は、データベースのテーブルカラムサイズと同期を合わせる などの
目的に使われていることが多いかと思いますので、データベースとの関連を考慮しながら検討してください。
結合文字判定
結合文字であるかどうかの判定ですが、正規表現(Javaのjava.util.regexパッケージ)を使用することにより、ある程度の
判定が行えました。
Unicodeでの判定である \p{プロパティ} を使用し結合文字のカテゴリM (\p{M}) や もう少し細かいカテゴリとして
Mn(字幅のない記号) などを指定します。
上記の方法で、結合文字がすべて解決するかどうか? は保証しかねますので、動作確認は各自お願いします。
また、より良い判定方法があれば、ご連絡いただけるとありがたいです。
※参考URL
java.util.regex.Pattern#ubc
UNICODE CHARACTER DATABASE
PDF 千夜一夜/PDFと文字 (35) – 文字の合成方法
結合文字の扱いの注意点
結合文字はサロゲートペア同様、2つの文字を組み合わせて1つの文字を生成するため、 文字桁数 や 文字バイト数 を取得して使用しているプログラムでは注意が必要です。
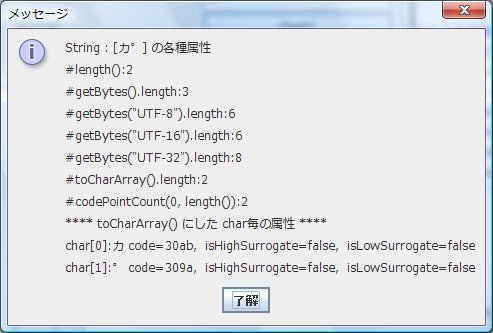
結合文字である 0x00030AB,0x000309A の文字情報を Javaにて取得すると、
上図のようになります。
String#length() = 2 になり、String#getBytes().length = 3 になってしまっているのもわかります。
たとえば、すべて全角を判断するようなロジックにて if (String#length() * 2 == String#getBytes().length)
のような記述は使用できません。
その他、結合文字での注意したい点として以下があります。
- すでに存在している基底文字を結合文字として入力される可能性がある
たとえば、「プ(U+30D7)」 はすでに基底文字が存在しますが、「フ + 0x000309A(゜) 」の結合文字としても作成出来てしまいます。 そうすると、見た目では同じ文字なのに、プログラムでは "違う文字"と判断してしまう ということが発生することになります。
この対応をするための処理として、「Unicode正規化」を一般的に行います。
マッピングの一覧は http://www.unicode.org/Public/UNIDATA/UnicodeData.txt に存在します。
(J2SE6.0からUnicode の正規化 クラス(Normalizer)が追加されているようです。)
(http://www.icu-project.org/のICU4JにてUnicodeJavaライブラリが提供されているようです。試してはいませんが、こちらも使用できるかもしれません。) - 片割れの1文字のみ消すことが出来てしまう
結合文字は 基底文字と結合文字 の2文字で1文字を表現していますが、 Swing JTextFieldにて試したところ、Deleteキーなどで文字を削除しようとすると片割れの1文字のみ削除 出来てしまうようです。
そのため、基底文字のみ削除された場合では 文字としての表現ではない結合文字 のみ残ってしまう事が 発生します。
メイリオとJ2SEバージョン
J2SE各バージョンを使用して、「Dialog」フォント と「メイリオ」フォント とを JLabelを使用して
表示してみました。
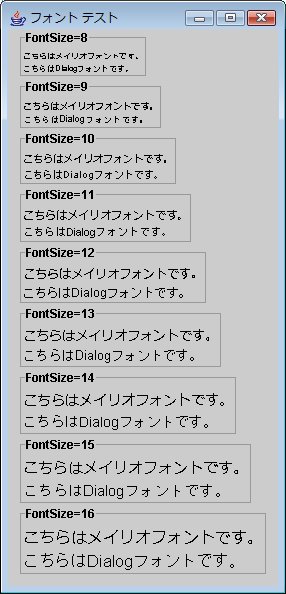
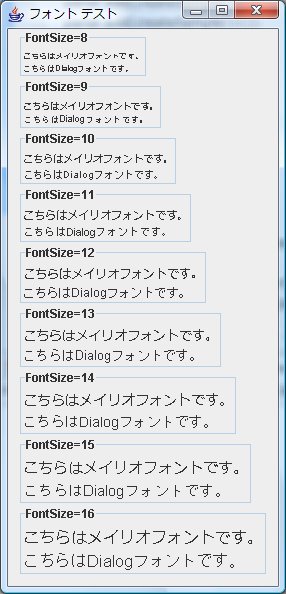
J2SE1.4, J2SE5.0 では残念ながらあまり綺麗には表示されないようです。
また、Dialogフォントと比べ文字の横幅が大きくなります。
- 図1.J2SE1.4.2_14
- 図2.J2SE5.0_13
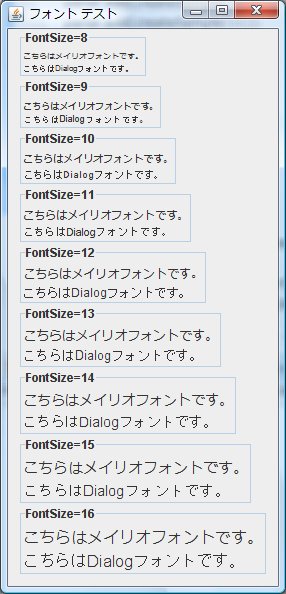
- 図3.J2SE6.0_03
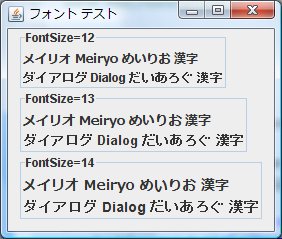
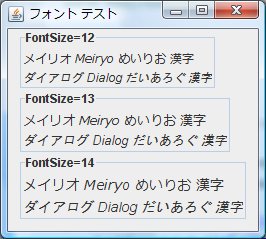
J2SE6.0_03にて メイリオフォントにて Font.BOLD, Font.ITALIC スタイルに変えて表示してみました。
メイリオフォントの日本語は Font.ITALIC は有効にならないようです。
参考までに J2SE7.0 beta23 にてFont.ITALICを試してみましたが、こちらでも有効にはなっていませんでした。
- 図4.J2SE6.0_03 Font.BOLD
- 図5.J2SE6.0_03 Font.ITALIC
メイリオ以外のフォント
結合文字 new String(new int[] { 0x00030AB,0x000309A }, 0, 2); //カ゜ を用いて 各種フォントにて JTextField上に表示を行ったところ以下のようになりました。
| MS ゴシック | MS 明朝 | Dialog | メイリオ | |
|---|---|---|---|---|
| J2SE5.0_13 |  | | | 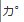 |
| J2SE6.0_03 | 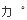 | | | |
| J2SE7.0_beta23 | | | | |
J2SE5.0_13ではメイリオでは正常に表示できますが、 MS ゴシック、MS 明朝、Dialog では正常表示はできないようです。
J2SE6.0_03 の MS ゴシックでは [カ] と [゜]は見た目上、2文字の状態になっており間隔が空いてしまいます。
この結果より、結合文字を使用許可する場合には、フォントは メイリオに変更した方がよいと思われます。